A Waiting Game Part 3
24 Mar 2018
Sometimes in trying to obtain the most useful set of features for predicting an outcome may require us to define new features based on the existing ones. I learnt this from the ‘Pytanic’ tutorial on kaggle, by Heads or Tails.
Hence I want to define a list of derived or engineered features:
‘AverageWaitTime’ - as in on average how many minutes one is willing to wait for someone regardless of whether that person is his/her superior, family, friend, or lover (one averaged value by averaging the 4 categories)
‘AverageMakeOthersWaitTime’ - as in on average one is comfortable making other people wait.
‘WaitSuperior%Difference’ - (WaitforSuperior - MakeSuperiorWait)/WaitforSuperior
‘WaitFamily%Difference’ - (WaitforFamily - MakeFamilyWait)/WaitforFamily
‘WaitFriend%Difference’ - (WaitforFriend - MakeFriendWait)/WaitforFriend
‘WaitLover%Difference’ - (WaitforLover - MakeLoverWait)/WaitforLover
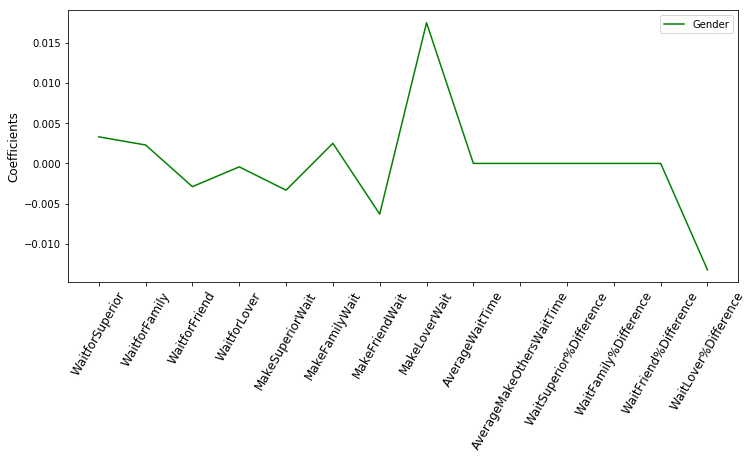
Using Lasso regression again to see which features matter:
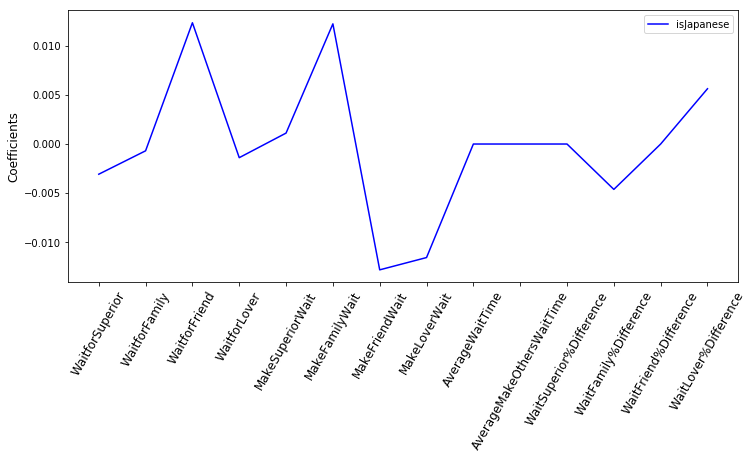
To predict whether the unknown subject is Japanese, only the derived features, ‘WaitFamily%Difference’ and ‘WaitLover%Difference’ seem to affect the prediction results.
As for predicting whether the subject is male or female, only ‘WaitLover%Difference’ should be included in the set of features.
With these in mind, I computed cross validation accuracy scores again,
x_isJ = df2.loc[:,['WaitforFriend','MakeFamilyWait','MakeFriendWait','MakeLoverWait','WaitFamily%Difference','WaitLover%Difference']]
y_isJ = df2['isJapanese']
x_G = df2.loc[:,['WaitforSuperior','WaitforFriend','MakeSuperiorWait','MakeFamilyWait','MakeFriendWait','MakeLoverWait','WaitLover%Difference']]
y_G = df2['GenderScore']
knn = KNeighborsClassifier(n_neighbors=3)
isJ_cv_scores = cross_val_score(knn, x_isJ, y_isJ, cv=4)
print('Predicting whether Japanese: ', isJ_cv_scores)
print('Mean: ', isJ_cv_scores.mean())
knn = KNeighborsClassifier(n_neighbors=3)
G_cv_scores = cross_val_score(knn, x_G, y_G, cv=4)
print('Predicting gender: ', G_cv_scores)
print('Mean: ', G_cv_scores.mean())Predicting whether Japanese: [ 0.88888889 0.88888889 0.875 0.5 ]
Mean: 0.788194444444
Predicting gender: [ 0.77777778 0.77777778 0.625 0.625 ]
Mean: 0.701388888889
With derived features, there is a slight improvement for predicting the natonality, while not much help for predicting gender.
Finally, let me introduce another useful modeling method for categorial dependent variable: the logistic regression.
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
x_isJ = df2.loc[:,['WaitforFriend','MakeFamilyWait','MakeFriendWait','MakeLoverWait','WaitFamily%Difference','WaitLover%Difference']]
y_isJ = df2['isJapanese']
x_G = df2.loc[:,['WaitforSuperior','WaitforFriend','MakeSuperiorWait','MakeFamilyWait','MakeFriendWait','MakeLoverWait','WaitLover%Difference']]
y_G = df2['GenderScore']
logreg = LogisticRegression()
isJ_cv_scores = cross_val_score(logreg, x_isJ, y_isJ, cv=4)
print('Predicting whether Japanese: ', isJ_cv_scores)
print('Mean: ', isJ_cv_scores.mean())
G_cv_scores = cross_val_score(logreg, x_G, y_G, cv=4)
print('Predicting gender: ', G_cv_scores)
print('Mean: ', G_cv_scores.mean())Predicting whether Japanese: [ 0.77777778 0.66666667 0.625 1. ]
Mean: 0.767361111111
Predicting gender: [ 0.88888889 0.77777778 0.75 0.5 ]
Mean: 0.729166666667
Using logistic regression, the accuracy score for predicting gender improved a little.
To summarize the cross validation accuracies using knn and logistic regression:
| knn (n_neighbors = 8) | knn (n_neighbors = 3) | knn with selected features only | knn with selected and derived features | logistic regression | |
|---|---|---|---|---|---|
| Nationality cv accuracy: | 0.61 | 0.67 | 0.76 | 0.79 | 0.77 |
| Gender cv accuracy: | 0.64 | 0.64 | 0.70 | 0.70 | 0.73 |